
In the past few posts, we’ve discussed how to read your data into pandas, and then manipulate it via calculations. At this point, we’ve come to the stage of deriving insights. To begin, this post discusses how to filter a DataFrame. Through filtering, you can focus on the part of your data that answers a specific question.
How to filter a DataFrame using Boolean indexing
Firstly, what is a boolean value? In summary, it is either True or False; akin to answering a “yes-no” type of question. Therefore, it is widely useful for filtering DataFrames. After all, when you filter data you are looking for whether it satisfies a specific condition. Hence, the answer (to whether your data satisfies the condition at hand) is always either True, or False.
Next, how do you use it in action? To demonstrate this, let’s return to the superstore data set*. Specifically, we want to filter to just the “Technology” product category. In order to get just the relevant portion of the DataFrame, we can filter it as below:
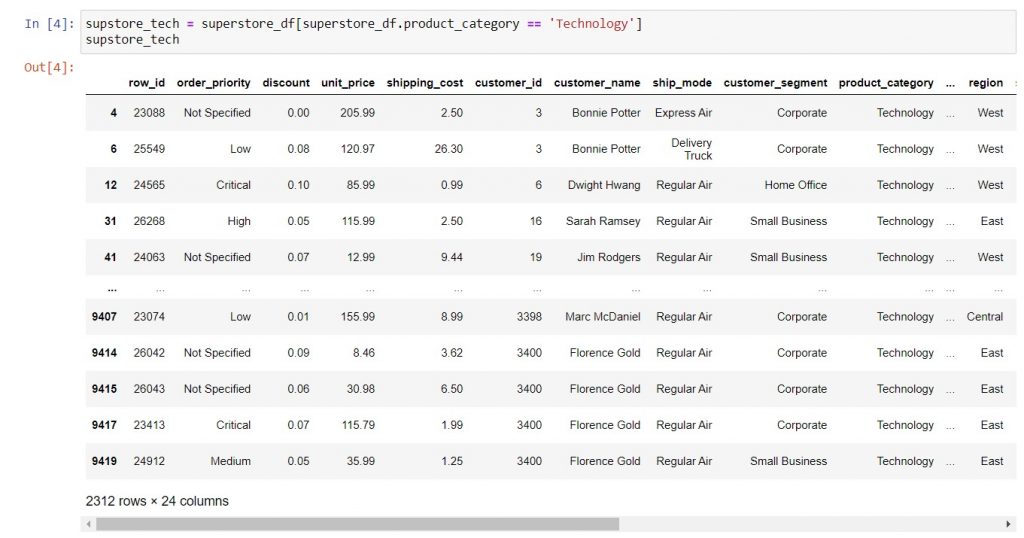
*To obtain the superstore_df DataFrame, download the Excel file at Page 6 of this document. Then use pd.read_excel to read the file, assigning the name as superstore_df (details in this post). Finally, rename the columns by replacing all spaces with underscores and all capitals to lowercase, as described in this post.
Syntax: filtered_dataframe_name = dataframe_name[dataframe_name.column_name == desired_value]
What’s going on under the hood here? First, when you write out the condition on a specific column, Python will check each row of that column to see if it satisfies the condition (True), or not (False). Next, Python will return only the DataFrame where the condition on the column is True. Hence, you get back a DataFrame, which is a subset of the previous DataFrame that you filtered. This subset contains only the rows that satisfied the condition.
Things to note about the syntax:
- You can only refer to a column using dataframe_name.column_name if the column name has no spaces. Conversely, if there are spaces, you can either use dataframe_name[‘column_name‘] or rename your columns using the approach in this post.
- Remember that if you’re filtering for a text value, you must put it in single quotation marks. Also, you must capitalize everything exactly as it will appear in the DataFrame.
- Recall the usual conditional operators in Python: == (equals), != (not equals), >, <, >=, and <=.
- You can combine more than one condition; in this case, you must enclose each condition in round brackets, with further brackets to group conditions that must be evaluated together.
- Furthermore, you must use the operators & (for “and”) and | (for “or”) to combine multiple conditions.
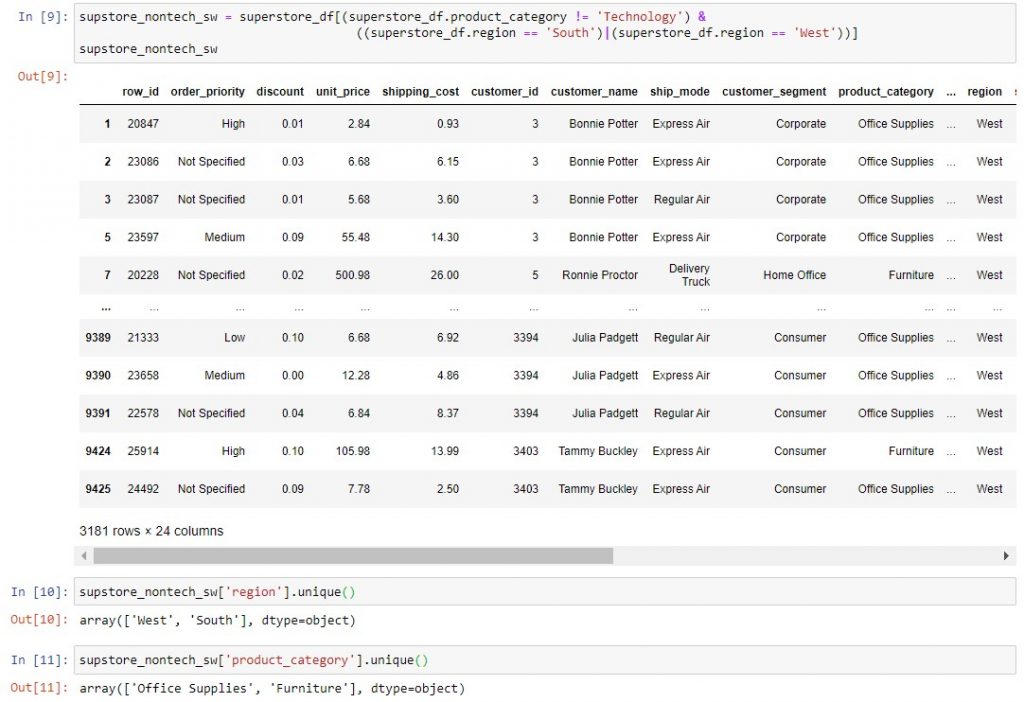
Below is an example where we filter the superstore DataFrame for product categories that are not Technology, and the region is either South or West. Notice how the brackets are placed to ensure that Python evaluates the conditions in the desired order, and also that the result is a DataFrame. Lastly, note how you can use .unique() to validate that the filters worked correctly.
How to filter a DataFrame on dates
I’m starting to sound like a broken record here: for business data, filtering on dates is very common, and therefore important to learn. Let’s look at your options:
- Extract the date parts that you might want to filter on (e.g. year, month, quarter) using pd.to_datetime and lambda as described in this post. Then, use the syntax just described above to apply ==, >=, <=, >, or < conditions on the date parts.
- Use .between to establish the start and end dates for the time period that you want to filter. For example, you can filter the superstore DataFrame for orders made in July 2012 as below:
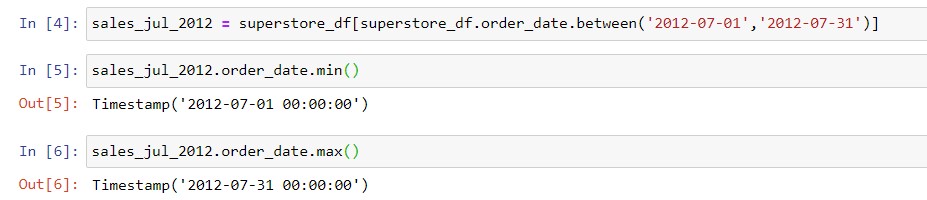
Be careful in choosing the start and end dates when using .between! As seen above, Pandas stores both date and time information. Also, it cuts the end-date off at midnight. Hence, if you had any orders with a time on Jul 31 2012 after midnight (e.g. 8 am, 4 pm etc), they would not be in the filtered DataFrame. Instead, to include all Jul 31 orders, you would need to filter superstore_df.order_date.between( ‘2012-07-01’ , ‘2012-08-01’ ). Therefore, always check whether your date columns record only the date (i.e. all times are midnight) or if they record the time as well.
In this post, we’ve covered:
| Things you would do in Excel | Equivalent task with Jupyter notebooks |
| Use filter icons on a header to filter for values in a column. | Use Boolean indexing to filter on a condition in one column |
| Apply filters to multiple columns of data. | Combine different criteria using round brackets and the & and | operators. |
| Filter on date columns. | Use the .between method to filter for data between a given start and end date. Remember to end at your desired end-date if your data has only the date (all time-stamps are midnight), but at your desired end-date + 1 day if your data has time-stamps. |
Technical references
| Questions or concepts from this post | Links to relevant documentation |
| Boolean data type | Python official documentation on definition of Boolean data type: here and here. Combining Boolean conditions (truth value testing) – Python official documentation here. |
| More details and options on filtering a DataFrame using Boolean indexing | Pandas official documentation is here. This is a far more detailed and technical explanation of Boolean indexing, written by one of the authors of Pandas 1.x Cookbook. |
| More details on the .between method | In general – .between operates on any values that can be sorted (numerical, alphabetical as well as time). Pandas official documentation is here. |
| .query method | If you’re used to SQL and want your Python code to look similar, you can try the .query method. It will function similarly to Boolean indexing, only the syntax is different. Pandas official documentation is here, and a few articles with examples are here, here, and here. |