
My intention is to help you understand every line of code posted. As such, I need to explain the concepts of loops and list comprehension. Consequently, you will be able to follow and reproduce the function written in this post.
Loops help you make changes to every item in a list
OK, so I am over-simplifying here. Not every object that humans would interpret as a “list” is technically one in Python syntax. However, you get the idea. Any time we want to work with an “iterable” (i.e. an object containing multiple values), we need a loop to cycle through the items in it one by one.
Let’s start with the columns of the superstore DataFrame. To start, we have 27 columns where we’ve replaced the spaces with underscores, and set all letters to lowercase. Now, we want to capitalize the first letter in each word. As such, we need to separate the words in each column name, which we achieve with the str.split() method. We then get this:
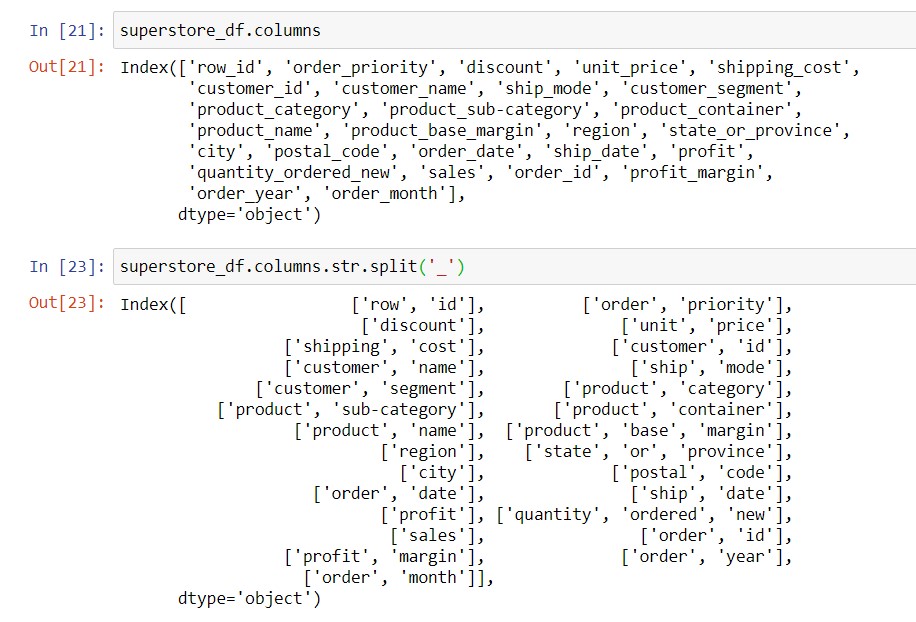
We have two list-like data structures: the Index which contains the 27 column names, and each column name which is a list of words. Therefore, we need to loop through each word, and then each column name. Let’s begin!
Indexing: Getting an item within a list
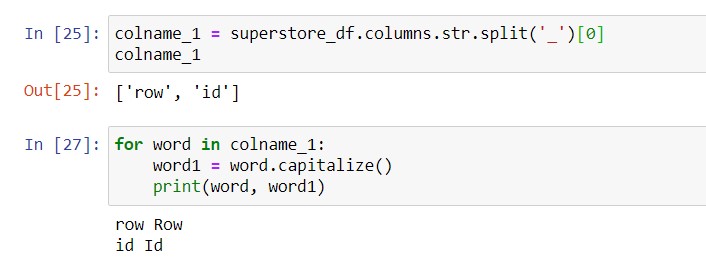
First of all, we need to find a sample column name, in order to build logic to capitalize the words. For simplicity, let’s take the first column. To do this, you put the index of the item (also called an element) you want to get within square brackets. Python starts counting at zero, so the first column name is at index 0, as shown below.

First loop: capitalizing every word in a column name
We want to change this from “row_id” to “Row ID”. At this point, we already split “row_id” into two words: “row”, and “id”. We now will write a loop to go through each of the 2 words in the list and capitalize them.
Within the code above, we only asked for the first letter in the word to be capitalized. However, let’s say we want “ID” to be in full caps. We can add an “if” statement (see this post) to put the word “ID” in full caps. Here’s our second try:
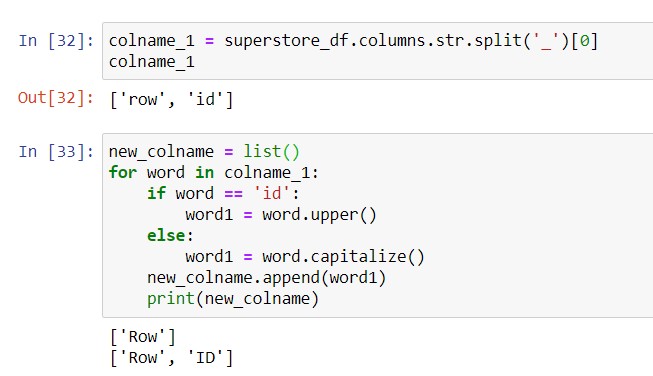
We can break the technical concepts behind the above code into 2 aspects: the syntax of the “for” loop, and the creation of a new list.
How to write a “for” loop
The diagram below shows the structure of a “for” loop. Actually, there are two types of loops in Python: “for” and “while”. However, since DataFrames have finite rows and columns of data, the “for” loop is usually your easier and safer option. If you want a deeper walk-through on loops, you can watch Python For Everybody‘s tutorials here.

Creating a list and adding new items to it
At this juncture, you might have noticed that lists are enclosed in square brackets. You have two options when you want to create a new list: either use empty square brackets, or declare the variable as list().
Usually, we add items to a list with the .append() method. For example, we expand the process of populating the new column name through printing the output of each part of the “for” loop below:
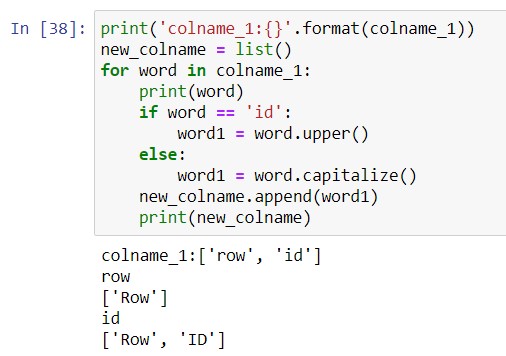
You’ll notice these aspects of the code:
- We have to create the empty list before starting the “for” loop. This ensures that each step of the loop will add an item to the list, not overwrite it.
- The “for” loop cycles through each item in colname_1. We have two items: “row” and “id”. It uses the “if” statement to decide how to modify each item.
- After modifying the item (each item is a string i.e. text), we append it to the new list. This is indented to be in the “for” loop but outside the “if” statement, because we want to finish the “if” logic before adding the modified word to the list.
Nested loops: writing a loop inside a loop
Finally, we need to create another layer of loops. Why is this? We started with 27 column names. Just now, we wrote a loop to modify the caps on each word within one column name. However, we want to repeat this process for every one of the 27 names. Therefore, we’ve got to write another loop with the first loop inside it.
By printing every step of the output, we can see how the code modifies each word in every column name, then puts them together, and then adds it to a list of new column names.

Finally, we can replace the old column names with the new ones, as below. Voila! Furthermore, if you’ve followed me up to this point, you actually know enough syntax to change anything you want about your DataFrame. Just do it step by step, item by item with “for” loops.

List comprehension does exactly the same thing as loops. It’s just less typing.
If “for” loops can do everything we want, why do we need to go one step further? Because loops can be wordy! So after you become used to reading loops, you’ll start wanting to save time by flattening them. That gives you fewer lines of code to read, and less typing to do!

I won’t trivialize this process by saying it’s easy as 1-2-3, because at the beginning, it isn’t. Still, I hope that this reference diagram will help you first to understand list comprehension in other people’s code, and then eventually to try it for yourself. Of course, it isn’t a panacea for all loops – it’ll only work for the types of “for” loops where you want the output to be a list.
Now that we’ve done loops and list comprehension, let’s thank NumPy one more time.
In all honesty, modifying column names may be the only time you need to write loops when working with business data in pandas. That’s because NumPy is designed to perform math between vectors (i.e. your columns of data). Therefore, between NumPy and your use of .apply and lambdas (see this post and this post), you can do many calculations on your columns without loops, just like in Excel. Most of the time, pandas uses NumPy in the background so you will only need to remember the pandas functions and methods, and just let NumPy do its job.
Technical references
No Pandas for Productivity post is complete without a set of when-you’re-ready-to-geek-out documentation references, so here we go!
To help you go to town with lists and string manipulation, you can go to these links for all the relevant methods:
| Python For Everybody textbook | Python official documentation | |
| Lists | Chapter 8 – Lists | List methods Common sequence operations Mutable sequence operations Sorted() function The Python Tutorial on lists and list comprehensions |
| Strings | Chapter 6 – Strings | String methods |