
As you pull your data more often, you may encounter situations where you need more complex joins than what we’ve previously discussed. Here are some examples:
- You’re looking for something that did not happen: e.g. products without orders in the past 7 days. In this case, you need an outer join. Specifically, you would pull all products, then left join against a pull of all products that had sales in the past 7 days.
- The relationship between two tables involves matching on more than one column. For instance, you deploy the same marketing campaign on 3 different websites. Then, you may need to join data on both the marketing campaign and the website name to get accurate data.
This Kaggle notebook contains all the code you need to follow along with the examples. Run cells 1 and 2, then go straight to cells 14-19 (Chapter 6).
Complex joins part 1: Using left, right and full outer joins
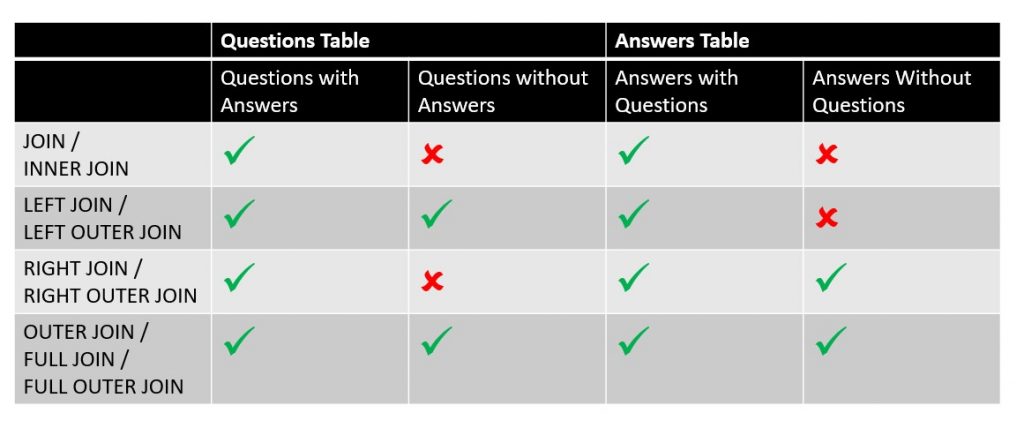
There are four types of joins: inner, left, right, and outer. This link has a concise and pictorial explanation of the 4 join types. Additionally, your SQL book should have a chapter explaining the join concepts in detail.
Outer joins: Stack Overflow example
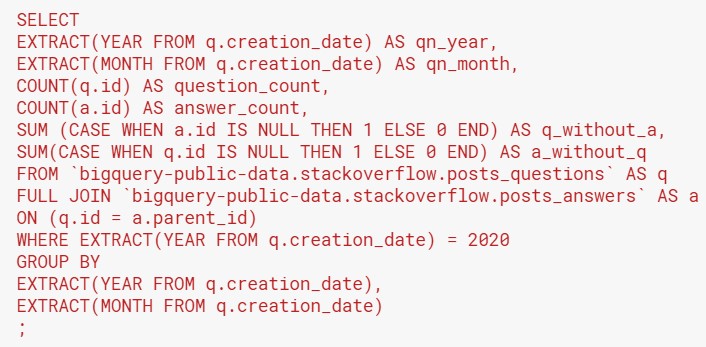
Putting this into practice, let’s use the posts_questions and posts_answers tables in BigQuery’s stackoverflow data. The questions table contains all questions that were posted in Stack Overflow. Answers to these questions are in the answers table, with the parent_id column showing the id of the question that the answer is for. Therefore, we will join the questions table to the answers table, matching the id of the question to the parent_id of the answer.
Let’s think about the following scenarios:
- Does every question have an answer? (Possible, but not necessarily).
- Would every answer have a question? (Most likely, yes).
How do different joins affect the data we get?
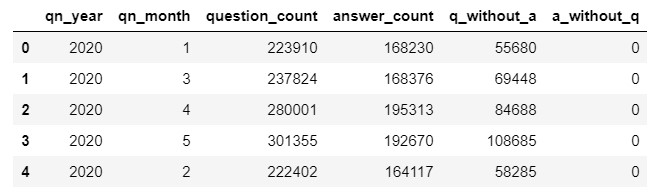
With a query like this, we can find out how many questions have no answers, and vice versa:
In the output, we can see that there were no answers without questions. Consequently, the same data will come back from a left join and an outer join. In contrast, if we used an inner join, we would miss out the questions without answers.
Complex joins part 2: Joining on multiple keys
Let’s now look at the Stack Overflow data set again. They have a stackoverflow_posts table containing information about all posts. If we join this to the posts_answers table, we can get information about the answers given to different posts. This is an overview of the column names, which are the same in both tables:
Just like the previous example, we would expect that the parent_id of the answer should match to the id of the post. Furthermore, the posts table contains information on whether the answer was accepted. There is an accepted_answer_id column, which contains the id of the answer that was accepted. So, if we only want to look at accepted answers, we need to ensure that both columns match, namely:
- The id of the post matches the parent_id of the answer, and
- the accepted_answer_id of the post matches the id of the answer.
Such a query looks like this:
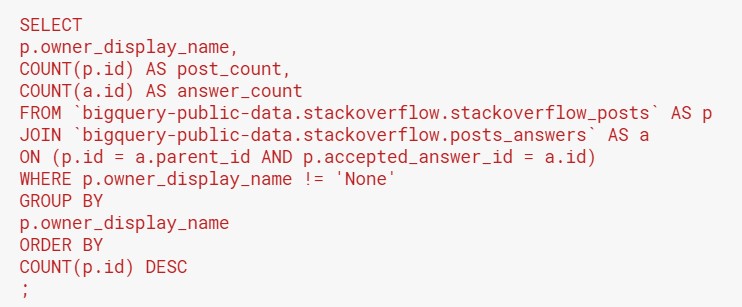
When we look at the results, the number of posts is always the same as the number of accepted answers. This shows that we have captured a one-to-one relationship between each post and the answer that the post owner accepted.
Not joining on all possible matching keys can create duplicates
On the other hand, let’s see what we get when we join only on one matching column, i.e. the id of the post matches the parent_id of the answer. The query and result would look like this:
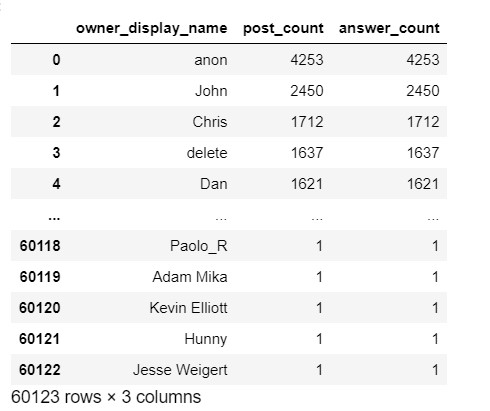
What do you notice? As expected, the number of answers increased because we are now counting answers which were not accepted, in addition to those that were. Surprisingly, the number of posts also increased! This is because the post will repeat for every answer that is associated with that post.
Troubleshooting possible duplicates in your data
To get an idea of the number of non-repeated posts, let’s pull the number of unique posts that the owner “anon” created with an accepted answer:

We found 1,123 unique posts with owner name ‘anon’. In other words, the second query is over-counting the number of posts. When we match the accepted_answer_id from the posts table to the id of the answers table we get 1,118 posts. Thus, there are five posts where there is a mismatch somewhere.
Key actions and take-aways:
- The first time you read this post, focus on getting a feel for the situations in your business that are similar to the examples described.
- You can then bookmark the post for future reference. Please use it in conjunction with your SQL reference book – the book will give you details of the mechanics and syntax of different joins, whereas my post gives you a feel for what might go wrong and possible directions to explore.