
Why is SQL necessary and useful? In essence, we have huge amounts of data and SQL enables us to extract what we need for specific business insights. So, filtering with the “WHERE” clause is a crucial part of using SQL.
This Kaggle notebook contains all the code for following along with the examples. Run cells 1 and 2, then follow along with cells 3-6 (Chapter 3)
Learning filtering in a targeted way
SQL has a plethora of operators for filtering, but you probably won’t have to memorize them all. To start, consider all the ways of slicing data that directly impact the talking points in your presentations. Most likely, pulling specific time periods is very important. Next, you know the business categories that pertain to your area of work. So, you should get familiar with the tables that contain attributes you want to analyze performance on.
Date filters: Things to note
Dates are critical to every business report. Incidentally, date formats and operators are the main area where different versions of SQL diverge. Thankfully, similar concepts still apply. In most cases, you want to manipulate dates in two ways:
- Filtering a data set for given time period, i.e. between a given start and end date.
- Defining a time period relative to the current date, e.g. last 7 days, last 90 days, etc.
To help you navigate your version of SQL, below are sample syntax in various versions of SQL to filter for the last 90 days of data. Also, links to the relevant date / time documentation are provided for each version. In addition, if you want to filter specific dates, you can express them in the format ‘yyyy-mm-dd’. The single quotation marks express the date as a string (text) format, which is how many computer programs read dates. Lastly, it will be useful for you to note that the mathematical operators “>”, “<“, “>=”, and “<=” can all be used for creating filters on date ranges.
| Version | Date subtraction syntax for today – 90 days |
| Hive | date_sub(current_date, 90) |
| Presto | current_date – interval ’90’ day |
| Microsoft SQL Server | dateadd(day, -90, current_timestamp) |
| MySQL | date_sub(current_date, INTERVAL 90 DAY) |
| IBM DB2 | add_days(current_date, -90) |
Why is date subtraction so important, in particular? It’s because it saves you a lot of time! If you set up your date filters to pull a desired time interval relative to the current date instead of typing in specific dates, you won’t have to edit that filter every time you rerun that query.
Filtering text: Exploring dimension tables
Chances are, you will often find yourself filtering categorical data. Most of the time, you’re interested in specific products, markets, etc and attributes thereof. And these types of information are most likely to be stored as text.
One of the most time-consuming aspects of getting acquainted with categorical data is that you might not always remember how names of different products / attributes are formatted in your data system. So before using SQL intensively, you will want to explore all the dimension tables that you are likely to filter with.
At the end of the previous post, you would have used the sample query from your analytics team to get that information. Now, you need to take the next step of exploring the unique values that are in the specific data columns that you’re interested in working with. For this, you can use a “SELECT DISTINCT” statement. In this example, I want to see what country names there are in Google BigQuery’s public data on global air quality. The query looks like this:

After running the query, the output is surprising. Instead of country names, the countries are listed by their 2-letter country codes. Such information is useful for my reference if I want to pull data for a particular country or countries in future.
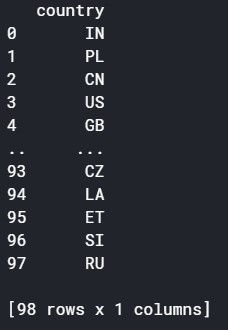
Dealing with capitalization in text data
A pair of useful text functions to learn are UPPER() and LOWER(), which set all the letters in a given text string to uppercase and lowercase respectively. Often, you’ll find it hard to remember the capitalization of your text data. For example, I might want to filter the air quality data on specific city names. However, the city names sometimes use all uppercase, and sometimes a mix of uppercase and lowercase.
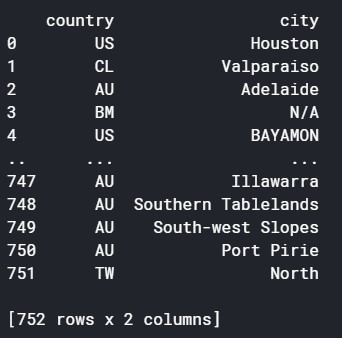
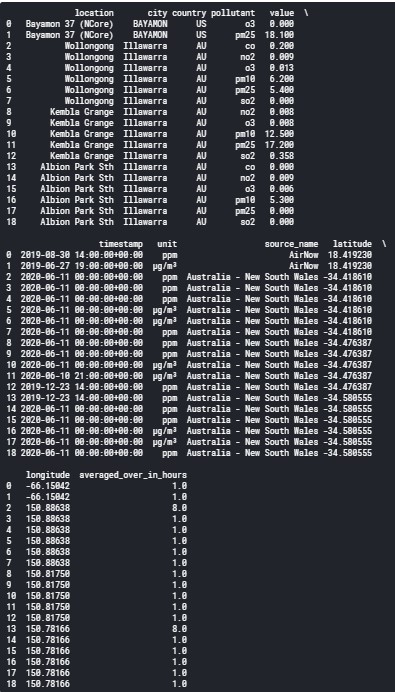
But if I use upper() to search for the data for specific cities, I don’t have to worry about the inconsistent capitalization. This query pulls the data for two cities which are capitalized differently in the table:

The UPPER() function set all letters in the city name to uppercase. So, I got the data for both Illawarra and Bayamon without memorizing the exact capitalization of either city name.
Key actions and take-aways:
- Familiarize yourself with the date formats and date functions for the SQL version in your company. Focus particularly on date subtraction relative to current date, and filtering for different date ranges that are relevant to you.
- Go through each dimension table that you are likely to filter categorical data on, and use SELECT DISTINCT statements to get the unique values of the data that you need. You can then write a few sample filters that you’ll commonly use, and store them as a .txt file in Notepad to copy paste when required.