
You’ve got a first query from your company, and you’re ready to start making sense of it. First of all, you’ll want to look at the FROM clause, which tells you where your data is coming from. Then you’ll find that you are looking at your first SQL joins. But most SQL books aren’t going to start there. So, that’s why we’re going to jumble things up a bit in our exploration of SQL queries and start from the middle of the book.
What your first SQL joins will look like
If you look at the FROM clause in your query, it will probably be something like this. And so these will be the first SQL joins you need to understand:

Why do we need so many tables?
Let’s revisit the problem statement your query needs to address. Most likely, it is pulling data from a record of your company’s orders. After all, sales performance is usually what’s first and foremost on your mind. Well, let’s think about all the key information that you’ll want to know about your sales:
- Which products were sold?
- If a product has different models, which models are performing better than others?
- What are the top product categories?
- What are your top customers like (age, gender, location etc)?
Now that we’ve identified some examples of the information we want, let’s look at the level of detail that each of these is grouped at. Your sales volume, which forms the backbone of the query, is probably recorded order by order. Each order will be related to a particular product, and a particular customer. And most likely, the characteristics of the products / customers that are driving sales are an interesting part of your business story.
However, imagine now that all the product characteristics are stored in the same table with your orders, and have to be repeated every time someone ordered that product. Furthermore, they’re repeated so many times that at some point, somebody is going to make a mistake in entering the data.
Relational databases store data more efficiently and economically
Now, you understand why the product characteristics need to sit in a separate product table. When all information pertaining to a product only needs to be updated in one place, it will safeguard against potential inconsistencies. Also, storing text information takes up more space than storing numerical data. Chapter 15 of Python For Everybody by Professor Charles Severance explains this very well, with the video version of this explanation here.
Furthermore, take any product in your company. To get a holistic assessment on its performance, you won’t just be looking at orders. In addition, you will also want to know how it’s doing in many other aspects. For example, customer reviews, shopping trends, returns, and other metrics might all be important to you. Most likely, each of these metrics are complex enough to need their own table. So whenever you assess product performance for any of these different sets of data, you want product characteristics to be captured consistently and accurately. And when your company stores the product attributes in a dedicated table that you can join to any of these other tables as needed, such consistency can be assured.
Writing your first SQL joins
Now you understand why these joins are necessary. The next step is to understand their structure. Then, you can confidently re-create them when you start pulling your own data. A sample join is below:
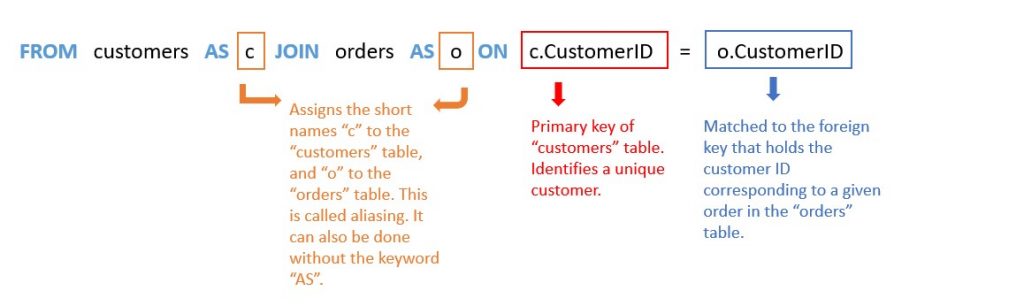
Primary and foreign keys are the most important concept for understanding the way a join is written. In Python for Everybody, the video explaining these terms is here. Most importantly, the name of the foreign key in one table might differ from the name of the primary key that it corresponds to in another table. So, you’ll have to be very careful about using the correct column names in the join.
Next, you’ll save time by assigning a shorter “nickname” to your existing tables, which is called aliasing. This is because for you to understand what’s in a table, the original name may need to be rather long. However, SQL only cares about knowing which table a column came from. As such, it will need you to specify the table of a column in the format tablename.columnname every time you mention any column in your code. If you use the full table name, you will probably spend a lot of time typing. So assigning just the first letter of the table name or some easy-to-understand “initials” can shorten the process.
Your SQL book will cover 4 different types of joins (inner, outer, left, and right) in their chapter. The outer, left and right joins are only relevant when you’re looking for data that is in one table but not in others. In this example you’re looking at sales performance over time. So, you’re only interested in the products that had sales, and the customers who made purchases. Therefore, the only join you will need is the “INNER JOIN”, which can also be referred to just as “JOIN”. It is the simplest of all the joins, and only brings back data that is in all the tables being joined together.
Key actions and take-aways:
- Find the fact table (the table containing the business metrics of interest) in your sample query.
- Identify all the foreign keys in that table that you might need to build joins on.
- Familiarize yourself with the dimension tables (i.e. product, customer, date etc) that you’ll need to join to your fact table to get other details you’ll need. Focus on knowing what the primary key is for each of these tables.
- Learn how to write a join, focusing on aliasing and getting the right column names for the foreign key and primary key to join on.