
As you progress, you’ll find situations where you need to combine more than one data pull to answer your question. In these situations, you’ll use subqueries and join or filter the results from these. Actually, you already have seen some subqueries in the examples from the last 2 posts.
This post aims to provide an example of a situation where you need subqueries. Also, it will outline the syntax of common table expressions (CTEs). These are a way of writing subqueries that make the code easier to read.
This Kaggle notebook contains all the code that you will need to follow along with the examples. Run cells 1 and 2, then go straight to cells 30-31 (Chapter 9).
Breaking a data question into 2 subqueries
Let’s revisit the example from Stack Overflow in a previous post on joins. We found that the user “anon” wrote 1,123 unique posts with an accepted answer. However, only 1,118 posts matched the answer with the correct parent post and the post with the correct accepted answer. How would we find out more about the 5 posts with mismatches?
To begin, we can break this problem into 2 parts. Firstly, we need to find the ID’s of the 1,123 unique posts and the ID’s of the accepted answers. The first subquery could look like this:
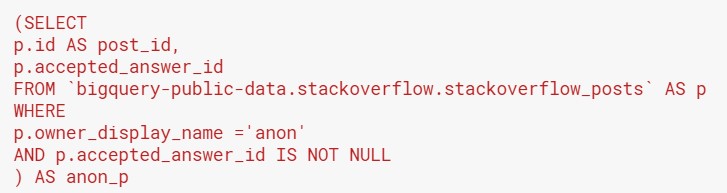
Secondly, we need to find the ID’s of the 1,118 posts where:
- the post’s accepted answer ID matched the answer ID, and
- the answer’s parent ID matched the post’s ID.
This is the second subquery:
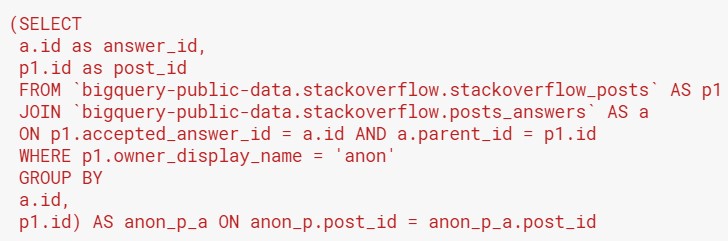
At this point, both subqueries should look familiar, because they are exactly the same as the queries in the earlier post!
Joining the results of subqueries
Thirdly, we need to determine which posts were in the list of posts written by ‘anon’ (subquery 1) but not in the list of posts that matched an answer ID in the answers table (subquery 2). To simplify, we are looking for data in subquery 1 which is not in subquery 2. That means we can find this by left joining subquery 1 to subquery 2, and then finding the rows where there was no data from subquery 2. We are looking for posts that don’t have a match, so we join on the post ID.
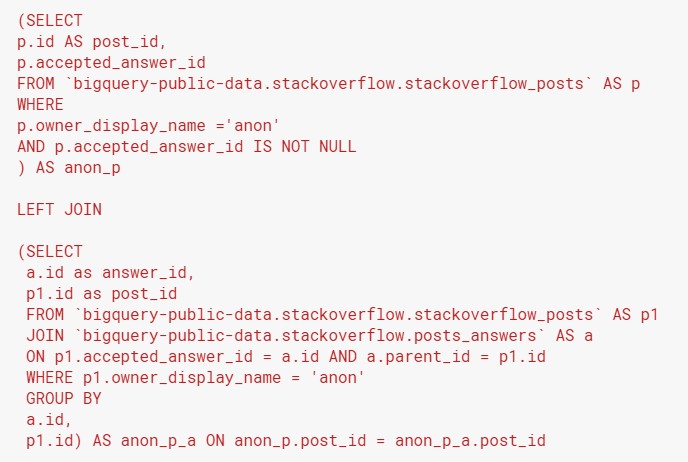
Using IS NULL to find cases where there isn’t a match
We need to find the posts that were not in subquery 2. This means that the post ID’s would appear in the query that we’ve named anon_p, but not the one that we named as anon_p_a. Hence, we can find these with the clause “WHERE anon_p_a.post_id IS NULL”. You will see this later in the full query.
Why would you have a null? In the first query, you have pulled 1,123 post ID’s into a temporary table, named anon_p. Since this is a left join, the output will keep all 1,123 post ID’s in anon_p, regardless of whether they match a post ID in anon_p_a. However, for the 5 post ID’s that do not have a match in anon_p_a, the columns anon_p_a.post_id and anon_p_a.answer_id would be blank. SQL processes these blanks as null values.
Wrapping up: Finding the answer ID’s that have the mismatched posts as a parent
Fourthly, we want to know what the ID’s of the answers in the answers table (if any) were associated with these mismatched posts as parents. This involves another join. Again, we will LEFT JOIN because we have to consider that some of these posts might have an accepted_answer_id that does not correspond to any answer in the Answers table. This is the final query:

Common table expressions: a more readable way to write code with subqueries
If you are having trouble matching brackets in your subqueries or are lost in the logic, you could consider using common table expressions (CTEs). These are a way of writing all your subqueries at the top of your code, and then joining and filtering the results of these subqueries in a cleaner piece of code at the bottom. This link has an explanation and example for using CTEs.
Here’s the same query as above, re-written using common table expressions. You’ll see that the sequence of the code matches more closely with the sequence of our thought process.

- Technically, with CTEs the subqueries are creating new temporary tables. Write each of these queries inside brackets, separated with commas.
- You only need to use WITH once, at the beginning of the code.
- Unlike all other times when you use aliasing, for CTE you assign the alias before writing the code that defines what goes into the temporary table. This is the reverse of all other situations where you define what you want to alias before assigning the alias.
Key actions and take-aways:
- You will probably encounter subqueries and common table expressions in other people’s code before you start writing them on your own. Use this method of breaking down the logic to understand someone else’s queries.
- Most likely, your beginner SQL book won’t cover common table expressions. However, it’s useful to know that you have this option. You can then consider using them if a query with many subqueries is getting messy and confusing.