
When will you get missing values in your data? Quite often, actually! For instance, customer survey data where respondents did not answer every question. Or else, your company has some products that nobody bought. In order to deal with these situations, this post shows you how to handle missing values in your DataFrame.
Find missing values in a DataFrame
The first step to handle missing values is knowing how many of them you have, and where they are. When we use .isna() on a DataFrame, we get a DataFrame of True or False (Boolean) values. Either there is missing data (True), or there is valid data (False). Because True = 1 and False = 0, we can add them up to count the total number of missing values.
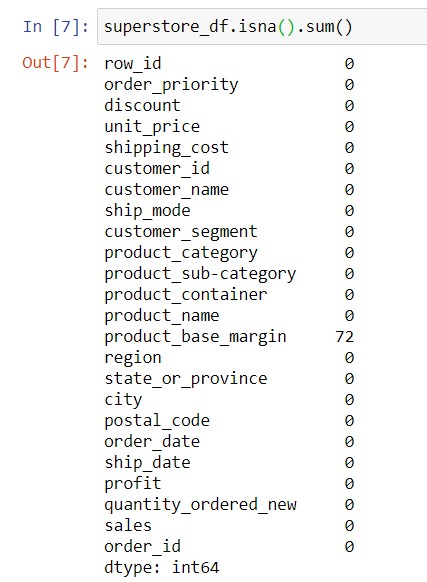
Syntax: dataframe_name.isna().sum()
In the above example, each column of superstore_df.isna() has True or False values depending on whether there was missing data. Thereafter, .sum() adds up the number of True values in each column. Hence, you can see that only one column, namely product_base_margin, has missing values. Specifically, 72 rows had missing data for product_base_margin.
Filter the DataFrame for missing values
Before you decide how to handle the missing data, you need to understand more about the circumstances. Thus, you will filter the DataFrame to pull just the affected rows. Refer to this post for the syntax to filter a DataFrame.
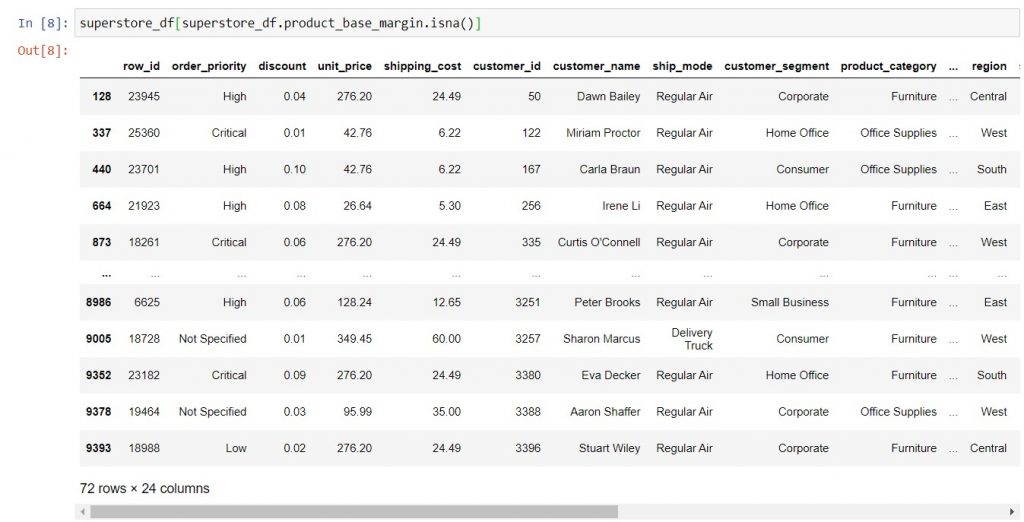
If there are too many rows and columns to display all the data in the notebook, you can write the output to a .csv file (see here) to examine it in Excel.
Decide how you want to handle the missing values
After you’ve examined the instances where missing values occurred, you can decide what to do about them. Usually, you will choose one of the following ways:
- Firstly, if the missing values result in the data not making sense, you might need to remove them. So, you can use .dropna() to do this.
- Secondly, if you know that the missing value should be zero (e.g. when you have products that had no sales during a time period), then you can use .fillna() to replace the missing values with 0.
- Thirdly, you might find some other way to estimate the missing value, and therefore write a function to replace it.
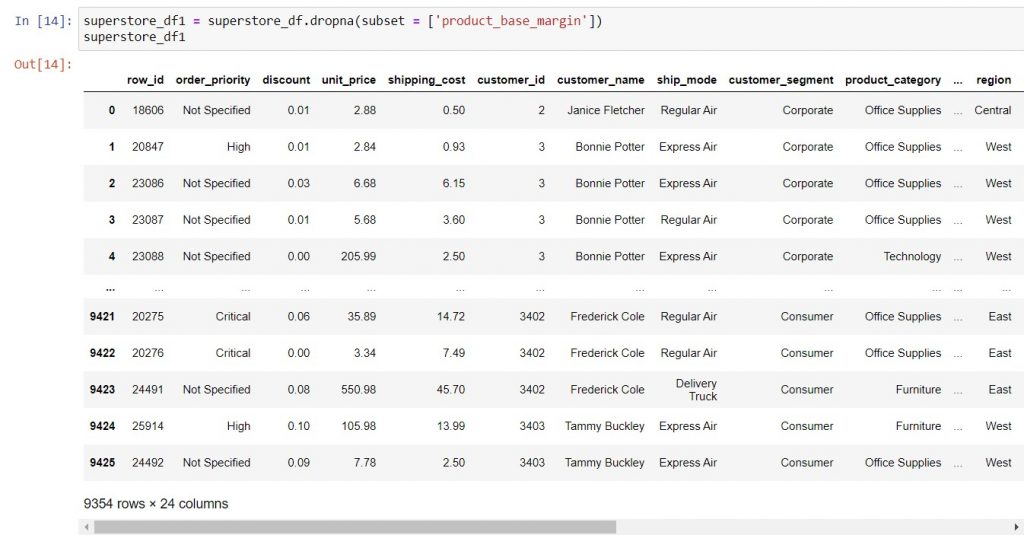
Syntax to remove missing values: dataframe_name = dataframe_name.dropna(subset = [‘column_name‘])
If you’re really confident, you can replace the DataFrame by giving it the same name, as above. Otherwise, you can also create a new DataFrame removing the missing values. In the example below, superstore_df1 takes only the data where product_base_margin is not missing. Therefore, it has 9,354 rows, i.e. 9,426 rows in the original less 72 rows with missing data.
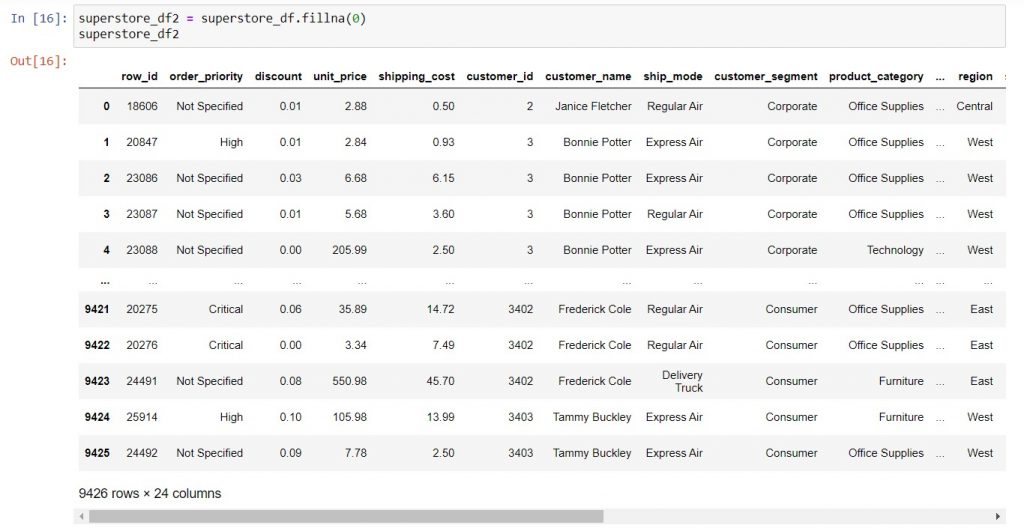
Syntax to replace the missing values with zero: dataframe_name = dataframe_name.fillna(0)
Suppose I want to replace all the missing values in my DataFrame with zero; this is when the above syntax will work. However, you need to be very careful if you have more than one column with missing values. In that case, you might want to apply .fillna() to one column at a time. Either way, you will retain all the rows of data; in this example, all 9,426 rows of data remain, unlike the first option where 72 rows were removed.
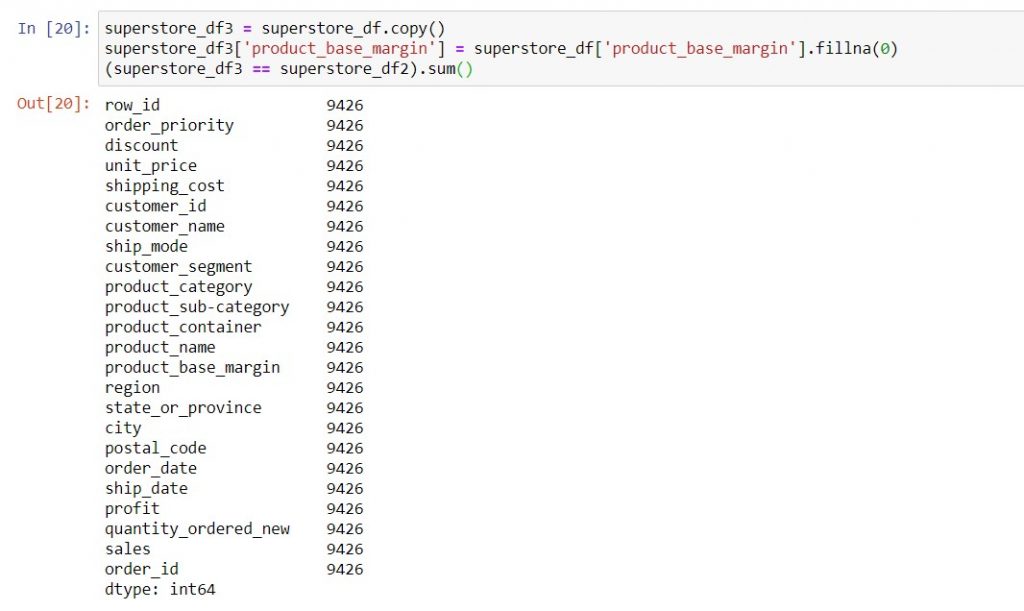
To demonstrate both approaches, I’ve created superstore_df2 by using .fillna() on the entire DataFrame, and superstore_df3 by using .fillna() on just one column. Because we had only one column with missing values, both approaches had identical results.
Final example: Write a function to design your own way to replace missing values
Actually, option 2 didn’t make a lot of sense for the superstore scenario, since we have valid data for profit and sales in the DataFrame. Hence, we can try estimating the profit margin using profit / sales. To achieve this, we can write a function, as explained in this post:
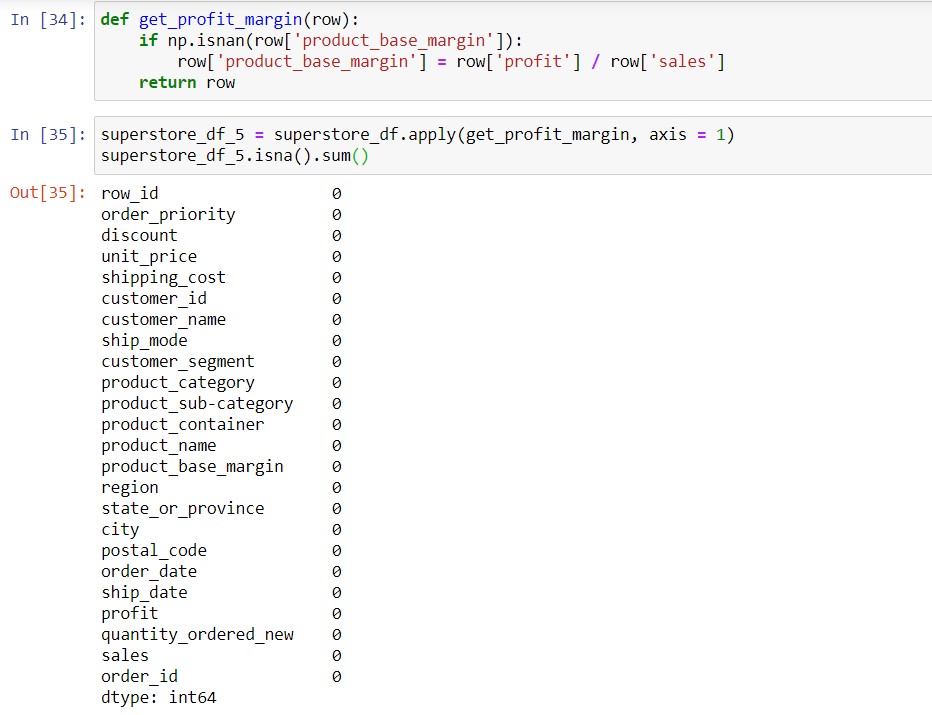
Note that in order to test whether there was a missing value or not, we used the np.isnan() function (see here). This is because the Pandas .isna() method only works on DataFrames, or rows / columns of DataFrames. However, once we pull one row of a DataFrame and look for the value in the product_base_margin column, we are dealing with a single value (a float). The np.isnan() function will return True if the value is missing (a null), and False if it isn’t.
In this post, we’ve covered:
| Things you would do in Excel | Equivalent task with Jupyter notebooks |
| Use “Go to Special” -> “Blanks” to find missing values. | Use .isna() or .isnull() to count and filter for missing values. |
| Manually remove blank rows from a worksheet | Use .dropna() to remove rows with missing values. |
| Fill blanks with values either using smart fill or add-ins. | Use .fillna() or write functions to fill in blank values. The former will work well if you’re filling all blanks with the same value, and the latter is better if you need to customize your calculations. |
Technical references
There are many more ways that you can use the methods mentioned in this post. Therefore, when you’re ready to explore more broadly, you can refer to the links below:
| Methods | Pandas documentation |
| .isna | Official documentation is here. Similarly, you might encounter .isnull() in older versions of code (Python 2). Conversely, .notna() and .notnull() are their opposites and will bring back non-missing data. |
| .dropna | Official documentation is here though the example in this post is the most likely way you will use this method. |
| .fillna | See here for description on all the possible keyword arguments. In addition to filling with zero or a fixed value, you can also do forward or backward fills. |